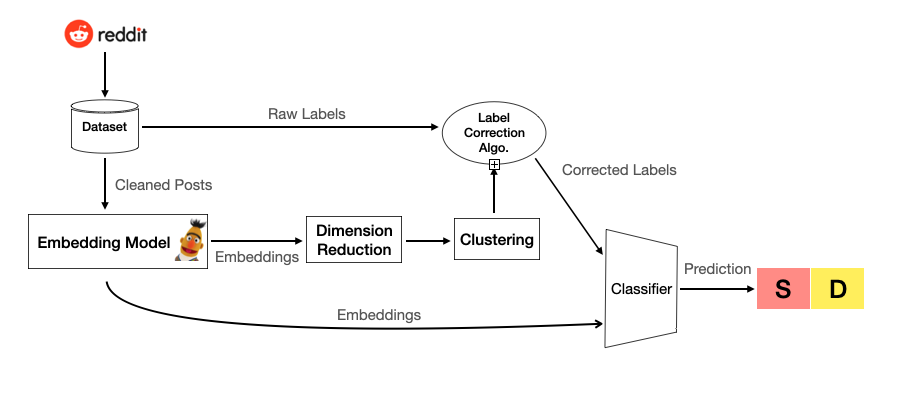
There are two ways of getting the prediction from our model.
We can get an average accuracy of 94% by method 1. Furthermore, the average accuracy increased to 96% by adding label correction algorithm.
Reference: "Deep Learning for Suicide and Depression Identification with Unsupervised Label Correction" by Ayaan Haque*, Viraaj Reddi*, and Tyler Giallanza from Saratoga High School and Princeton University. In ICANN, 2021.

Filter content length < 100 words (~150,000 data), remove URLs and Emoji, unpack contraction words and case normalization.
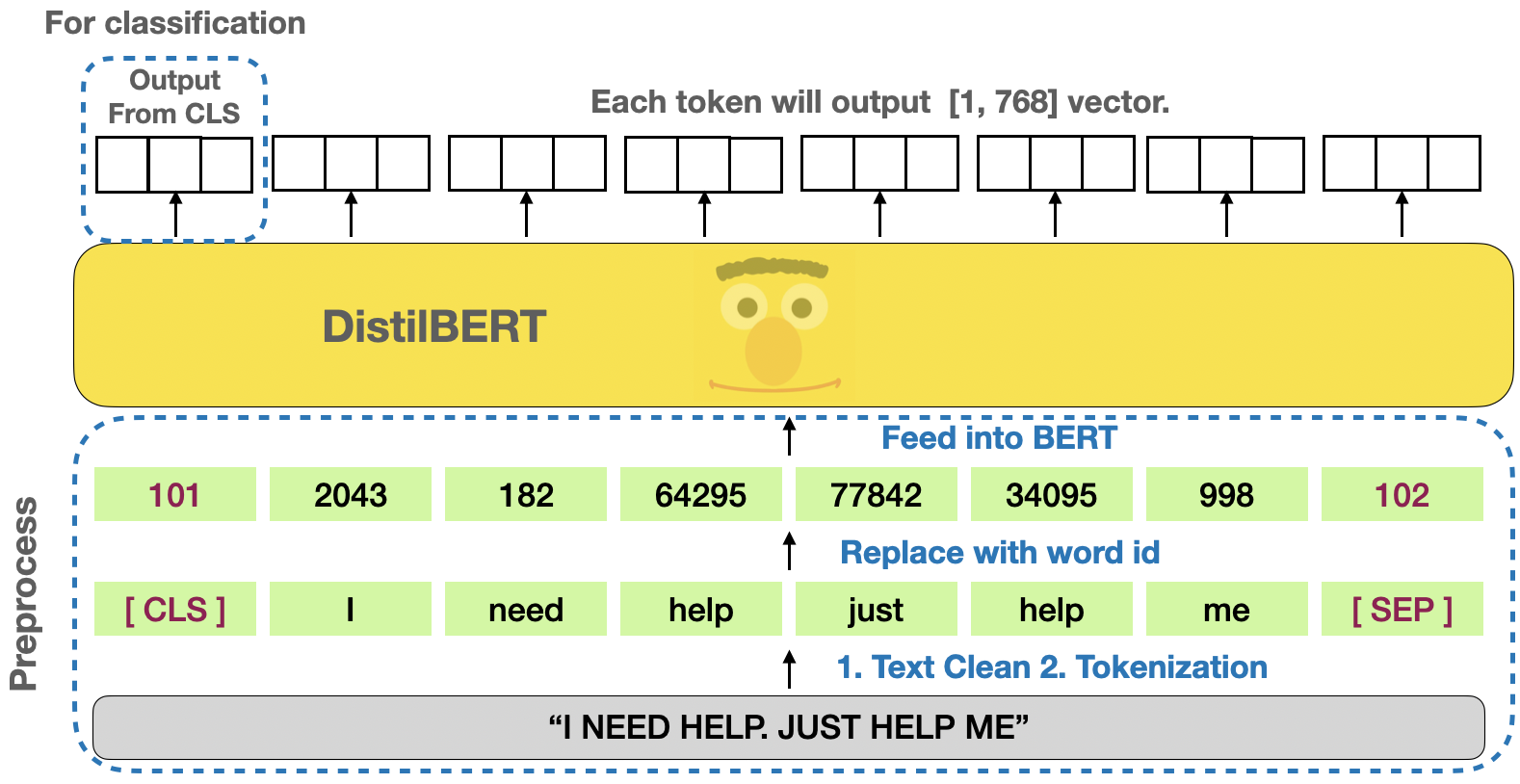
BERT (Bidirectional Encoder Representations from Transformers) is a popular transfer-based word embedding model. Instead of proceeding word by word sequentially like RNN/LSTM, it totally avoids recursion, by processing sentences as a whole and by learning relationships between words.
We feed 150,000 posts into distilBERT to extract only the dimension with [CLS] for our classification task.
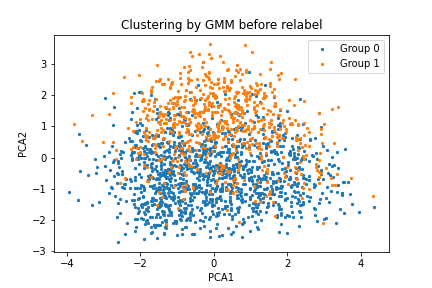
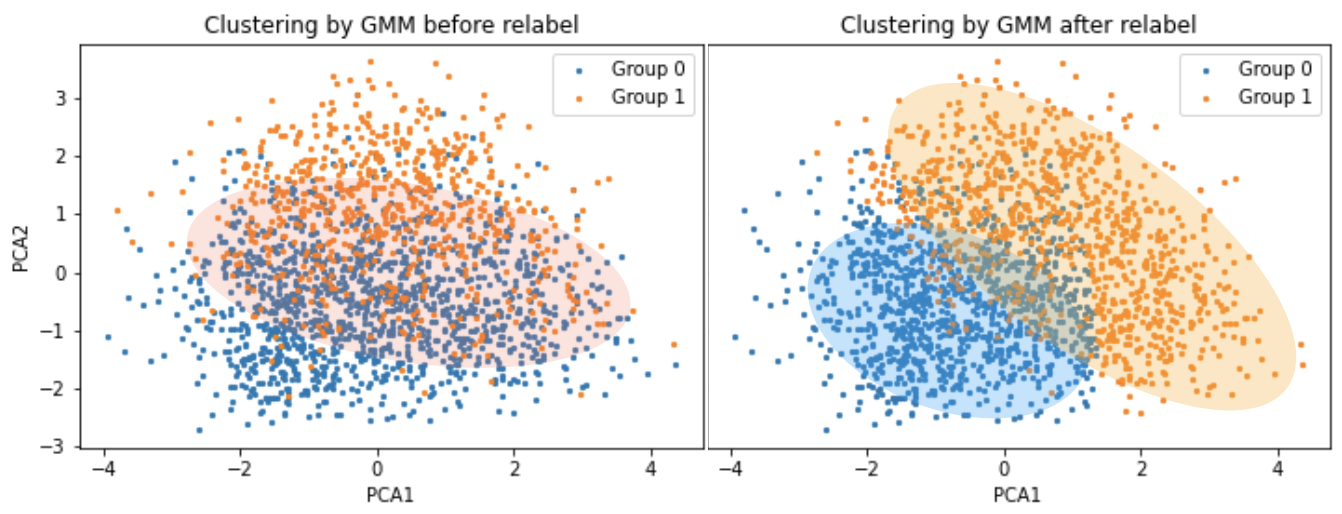
In this step, we use PCA (Principal component analysis) to decompose the data from (n, 768) to (n, 2) where n is the number of posts and 768 is the number of features extracted from BERT.
Cluster the data into two groups by GMM (Guassian Mixture Model) and Relabel the data which has different label with its initial.
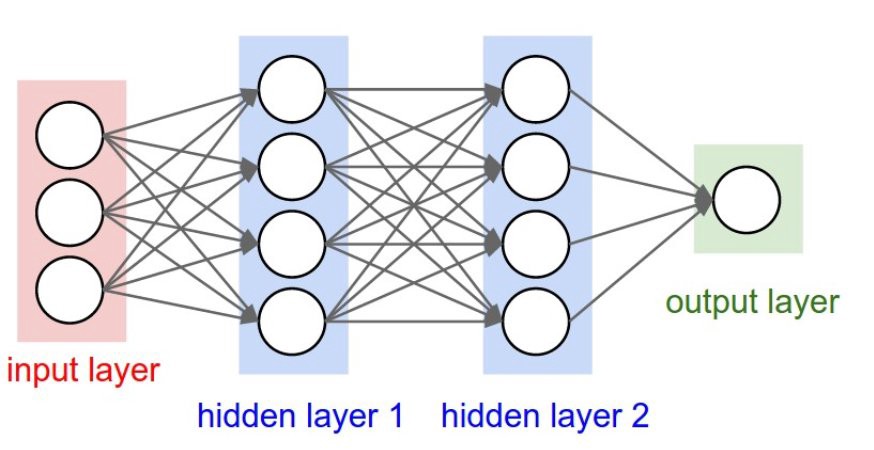
The network is composed of an input layer of size 768, a hidden ReLu layer of size 128, and another hidden ReLu layer of size 64. Output layer is a sigmoid activation layer. Adam optimizer is used with binary cross entropy for loss.
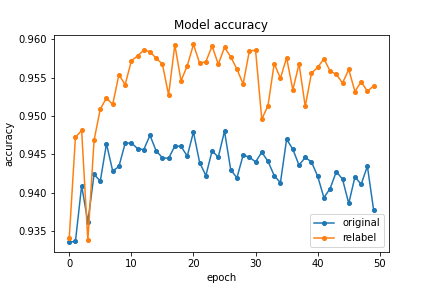
Our Fully Dense Network with unsupervised GMM clustering confidence correction achieved a 96% testing accuracy in successfully determining whether input sentences portray depressive or suicidal sentiment.
Presented by Chienpeng Huang, Jia-Hua Cheng, Aaryan Kothapalli